Amazon
Web Services provides different cloud computing infrastructure.
It
provides different IT resources on demand.
AWS
provides different services-
1.
IAAS(Infrastructure
as a service)
2.
PAAS(Platform
as a service)
3.
SAAS(Software
as a service)
AWS
provides different services like –
1.
Computing
2.
Storage
and Content delivery
3.
Database
4.
Security
5.
Data
Migration
6.
Networking
7.
Messaging
8.
Application
Services
9.
Management
tools
AWS
Computing –
AWS
EC2 -
EC2 is a RAW server, which is
resizable as per the needs. Resizable as when required.
AWS
Lambda –
Lambda does not
execute the application, it’ is used to execute the background task of
application. Like uploading an image.
AWS
Elastic Beanstalk-
It is used to host
an application. It is an automated from of EC2, create the environment and deploy
the code. Most of the software are already installed, just need to select the
required software like for java application select java and create the
environment and deploy you application while in EC2 nothing is preinstalled,
it’s completely raw server.
AWS
Elastic load Balancing-
Elastic load
balancing is used to distribute the workload on the deployed instances.
AWS
Autoscaling –
Autoscaling is
automatically handle the scale based on traffic, autoscaling and load balancing
works in parallel.
AWS
Storage Services:
1.
S3 is
object oriented file system. Create a bucket folder and then file can be
uploaded.
2.
CloudFront - Caged the website near to user
location to reduce response time.
3.
Elastic block storage- block level storage. One
EC2 can connect to multiple EBS.
4.
Glacier - Data archiving service.
5.
Snowball –Snowball is way to transferring data form/to AWS infrastructure
Physical
data transfer.
6.
Storage
Gateway works between data center and AWS cloud. Storage gateway take care of
data center failure.
AWS
Database –
1.
RDS
– Manages database, auto update, security patch etc.
2.
Aurora
– Amazon mySql which faster the mysql.
3.
DynamoDB
– Manages No-SQL db
4.
ElastiCache
- Distributed caching service
5.
RedShift
- Data ware house services, which is used to analysis of data. Analytic tool.
AWS
Networking –
1.
VPC
– Virtual private cloud, manage VPN for individual application cloud
2.
Direct
connect - direct connect to AWS
3.
Route
53 - domain name system.
AWS
Security Service –
1.
IAM- Identification
and authentication management
2.
KMS
- Key management service (Public/Private key infrastructure)
AWS
Application Service –
1.
SES-
Bulk emailing service
2.
SQS-
Simple Queue service
3.
SNS-
Simple notification service
AWS
Management Service –
1.
Cloud
watch
2.
Cloud
Formation - create could snapshot from existing cloud.
3.
Cloud
Trail - logging service
4.
CLI
– Command line interface of AWS
5.
OpsWorks
– Configuration management (Stack , layers)
6.
Trusted
Advisor – personal advisor from AWS
Security Group for EC2
Create a private key pair for EC2, follow below steps
Navigate to aws console aws-console
Navigate to EC2 dashboard and click on key-pair

Click on Create Key Pair button and provide kay oair name
 Now click on create it will download the private key file
Now click on create it will download the private key file

Create a private key pair for EC2, follow below steps
Navigate to aws console aws-console
Navigate to EC2 dashboard and click on key-pair

Click on Create Key Pair button and provide kay oair name


AWS
EC2 –
Follow below step to create EC2
instance-
Navigate to aws console aws-console
Select EC2 and navigate to EC2 dashboard
Here you can see all running EC2 instances existing key pair of secutrity groups.
To create new Ec2 instance click on launch instance as highlighted below

Now it will navgate to the EC2 configuration window
First select appropiate os image, selecting windows server
Now it will ask further configuration for
select type of instance and select t2.micro(free tier) and than select no of instance as follows-
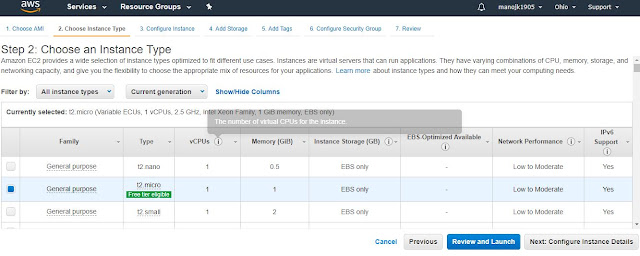
First select appropiate os image, selecting windows server
Now it will ask further configuration for
select type of instance and select t2.micro(free tier) and than select no of instance as follows-
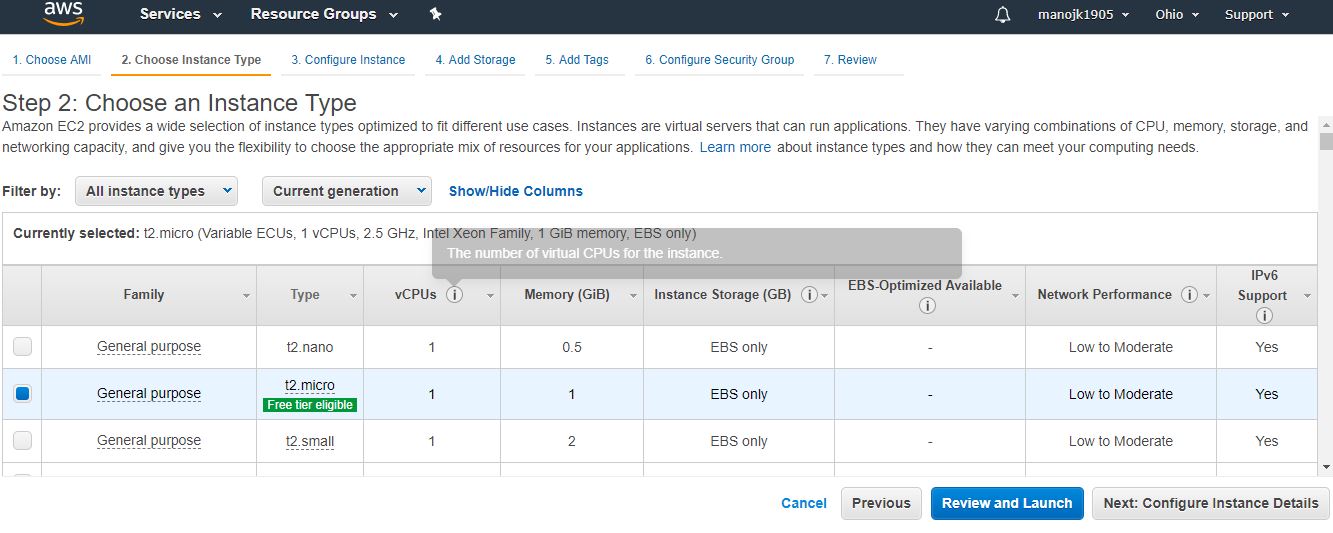

Now click on add storage & selct storage size by default it is 30 GB
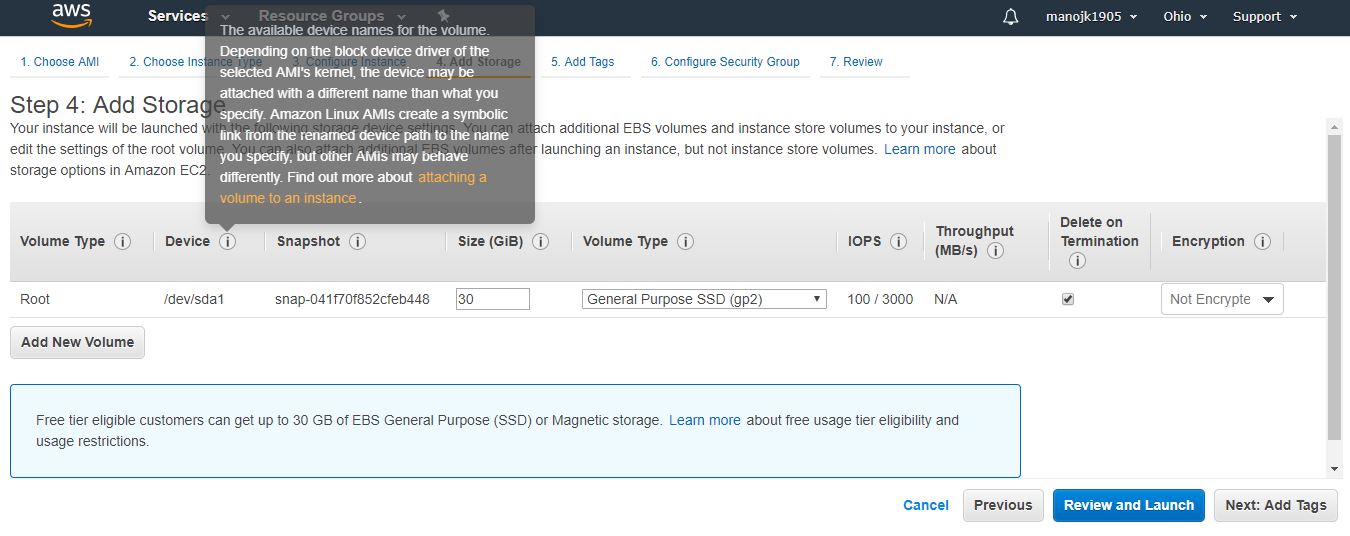
Than click on review and launch with default setting.
review screen -



Once the instance will up and running the status check will 2/2 check, now select the instance and below you can see the Ip, now we can connect with remote desktop to this EC2 instance with your security group.

